V8: Behind the Scenes (November Edition feat. Ignition+TurboFan and ES2015)
So this is my attempt to start a series of blog posts about what's going on behind the scenes of V8 in order to bring more transparency to what we do for Node.js and Chrome, and how this affects developers targeting either Node.js or Chrome. I'll mostly talk about stuff where I'm actively involved, so mostly things that are related to JavaScript Execution Optimization, new language features and a few tooling/embedder related issues.
Any opinions expressed in these posts are my own and don't necessarily reflect the official position of Google or the Chrome/V8 teams. Also these articles are clearly targeting the primary audience of V8 itself, which are developers utilizing V8 through Node.js, Chrome or some other embedder to build and deliver awesome products to the end user. I'll try to not only scratch the surface, but also provide some background information and interesting details whenever feasible.
In this first article I'm going to give a brief update on our ongoing work on the TurboFan compiler architecture and the Ignition interpreter, and the current progress on the ES2015 and beyond performance front.
An update on Ignition and TurboFan #

As those of you following the work on V8 somewhat closely have probably already figured out, we're finally starting to ship the new architecture for V8, which is based on the Ignition interpreter and the TurboFan compiler. You have probably also already spotted the Chrome (Ignition) and Chrome (TurboFan, Ignition) graphs on arewefastyet. These reflect two possible configurations, which are currently being evaluated:
- The Chrome (Ignition) aka
--ignition-stagingconfiguration, which adds the Ignition interpreter as a third tier in front of the existing compiler architecture (i.e. in front of the fullcodegen baseline compiler, and the optimizating compilers TurboFan and Crankshaft), but with a direct tier up strategy from Ignition to TurboFan for features that Crankshaft cannot deal with (i.e.try-catch/-finally,eval,for-of, destructuring,classliterals, etc.). This is a slight modification of the pipeline we had initially when Ignition was announced earlier this year. - The Chrome (TurboFan, Ignition) aka
--ignition-staging --turboconfiguration, where everything goes through Ignition and TurboFan only, and where both fullcodegen and Crankshaft are completely unused.
In addition to that, as of yesterday we are finally starting to pull the plug on fullcodegen for (modern) JavaScript features - that Crankshaft was never able to deal with - in the default configuration, which means that for example using try-catch in your code will now always route these functions through Ignition and TurboFan, instead of fullcodegen and eventually TurboFan (or even leaving the function unoptimized in fullcodegen). This will not only boost the performance of your code, and allow you to write cleaner code because you no longer need to work-around certain architectural limitations in V8, but also allows us to simplify our overall architecture quite significantly. Currently the overall compilation architecture for V8 still looks like this:
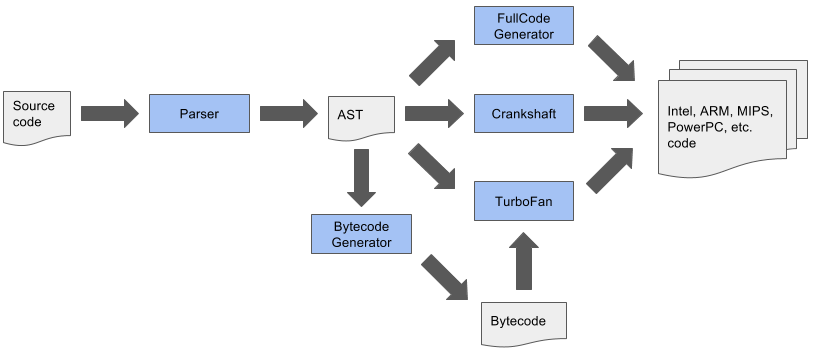
This comes with a lot of problems, especially considering new language features that need to be implemented in various parts of the pipeline, and optimizations that need to be applied consistently across a couple of different (mostly incompatible) compilers. This also comes with a lot of overhead for tooling integration, i.e. DevTools, as tools like the debugger and the profiler need to function somewhat well and behave the same independent of the compiler being used. So middle-term we'd like to simplify the overall compilation pipeline to something like this:
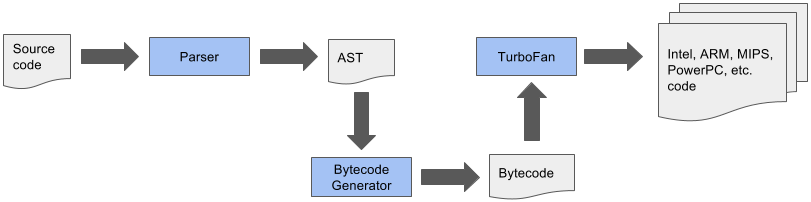
This simplified pipeline offers a lot of opportunities, not only reducing the technical debt that we accumulated over the years, but it will enable a lot of optimizations that weren't possible in the past, and it will help to reduce the memory and startup overhead significantly long-term, since for example the AST is no longer the primary source of truth on which all compilers need to agree on, thus we will be able to reduce the size and complexity of the AST significantly.
So where do we stand with Ignition and TurboFan as of today? We've spend a lot of time this year catching up with the default configuration. For Ignition that mostly meant catching up with startup latency and baseline performance, while for TurboFan a lot of that time was spend catching up on peak performance for traditional (and modern) JavaScript workloads. This turned out to be a lot more involved than we expected three years ago when we started TurboFan, but it's not really surprising given that an average of 10 awesome engineers spent roughly 6 years optimizing the old V8 compiler pipeline for various workloads, especially those measured by static test suites like Octane, Kraken and JetStream. Since we started with the full TurboFan and Ignition pipeline in August, we almost tripled our score on Octane and got a roughly 14x performance boost on Kraken (although this number is a bit misleading as it just highlights the fact that initially we couldn't tier up a function from Ignition to TurboFan while the function was already executing):
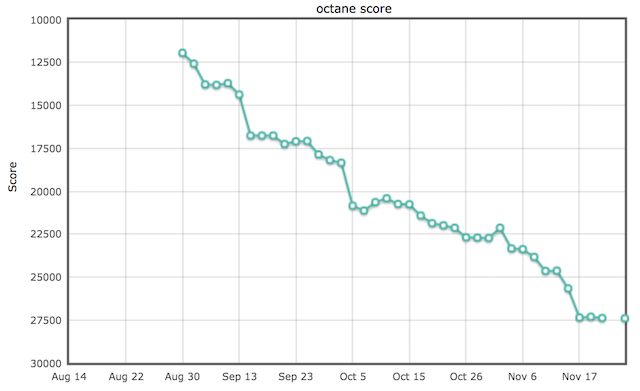
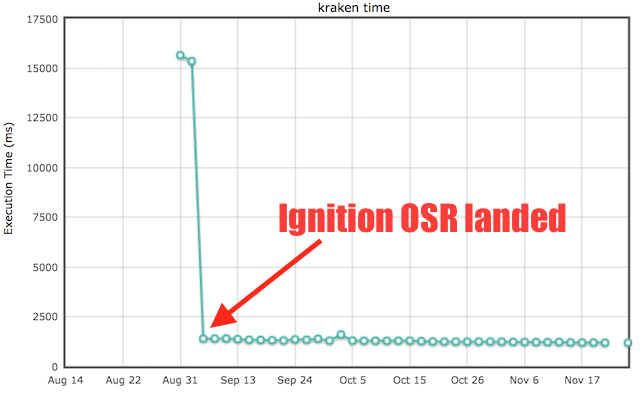
Now arguably these benchmarks are just a proxy for peak performance (and might not even be the best proxy), but you need to start somewhere and you need to measure and prove your progress if you want to replace the existing architecture. Comparing this to the default configuration, we can see that we almost closed the performance gap:
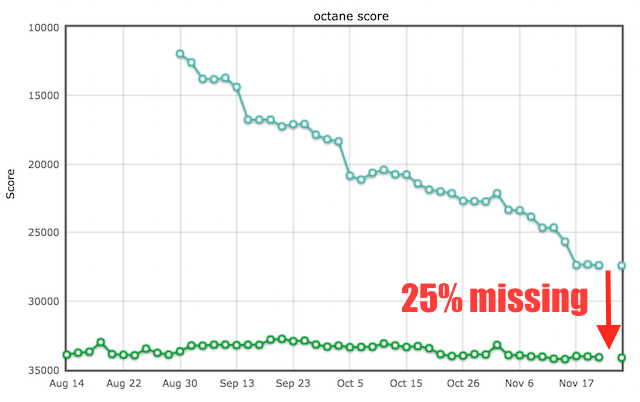
There are also a couple of benchmarks where TurboFan and Ignition beat the default configuration significantly (often because Crankshaft would bailout from optimization due to some corner case that it cannot handle), but there are also benchmarks even on Octane where Crankshaft already generates pretty decent code, but TurboFan can generate even better code. For example in case of Navier Stokes, TurboFan benefits from somewhat sane inlining heuristics:
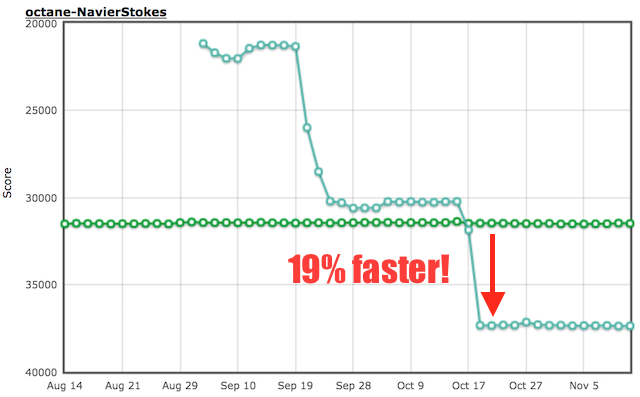
So stay tuned, and expect to see a lot more Ignition and TurboFan in the wild. We're constantly working to improve TurboFan to catch up with Crankshaft even in the old world (i.e. on the traditional ES3/ES5 peak performance benchmarks). We already gave a few talks internally at Google on TurboFan and TurboFan-related topics, i.e.
and we will now try to make as much of this information available to the public as possible (check the TurboFan page on the V8 wiki for additional resources). We also plan to give talks at various JavaScript and Node.js conferences next year (ping me if you would like us to talk about Ignition and TurboFan at some particular conference).
State of the union wrt. ES2015 and beyond #
The performance (and to some extend feature) work on ES2015 and ES.Next features is the other big topic that I'm involved in. Earlier this year we decided that we will have to invest resources in making ES2015 and beyond viable for usage in practice, which means that we must not only ship the fundamental feature, but we also need to integrate it with tooling (i.e. the debugger and profiler mechanisms in Chrome Developer Tools) and we need to provide somewhat decent performance, at least compared to the transpiled version (i.e. as generated by Babel or other transpilers) and a naive ES5 version (which doesn't need to match the sematics exactly). For the performance work, we set up a publicly available performance plan where we record the areas of work and track the current progress.
For finding horrible performance cliffs and tracking progress on the relevant issues, we're currently mostly using the so-called six-speed performance test, which tests the performance of ES6 (and beyond) features compared to their naive ES5 counterparts, i.e. not a 100% semantically equivalent version, but the naive version that a programmer would likely pick instead. For example an array destructuring like this
var data = [1, 2, 3];
function fn() {
var [c] = data;
return c;
}in ES6 roughly corresponds to this code
var data = [1, 2, 3];
function fn() {
var c = data[0];
return c;
}in ES5, even though these are not semantically equivalent since the first example is using ES6 iteration while the second example is just using a plain indexed access to an Array Exotic Object.
We are actually using a slightly modified and extended version of the performance test, which can be found here, that contains additional tests. All of these tests are obviously micro benchmarks, that's why we don't really pay attention to the absolute score (operations per second), but we only care about the slowdown factor between the ES5 and the ES6 versions. Our goal is to eventually get the slowdown close to 1x for all the (relevant) benchmarks, but at the very least get it below 2x for all of the line items. We made tremendous improvements on the most important line items since we started working on this in summer:
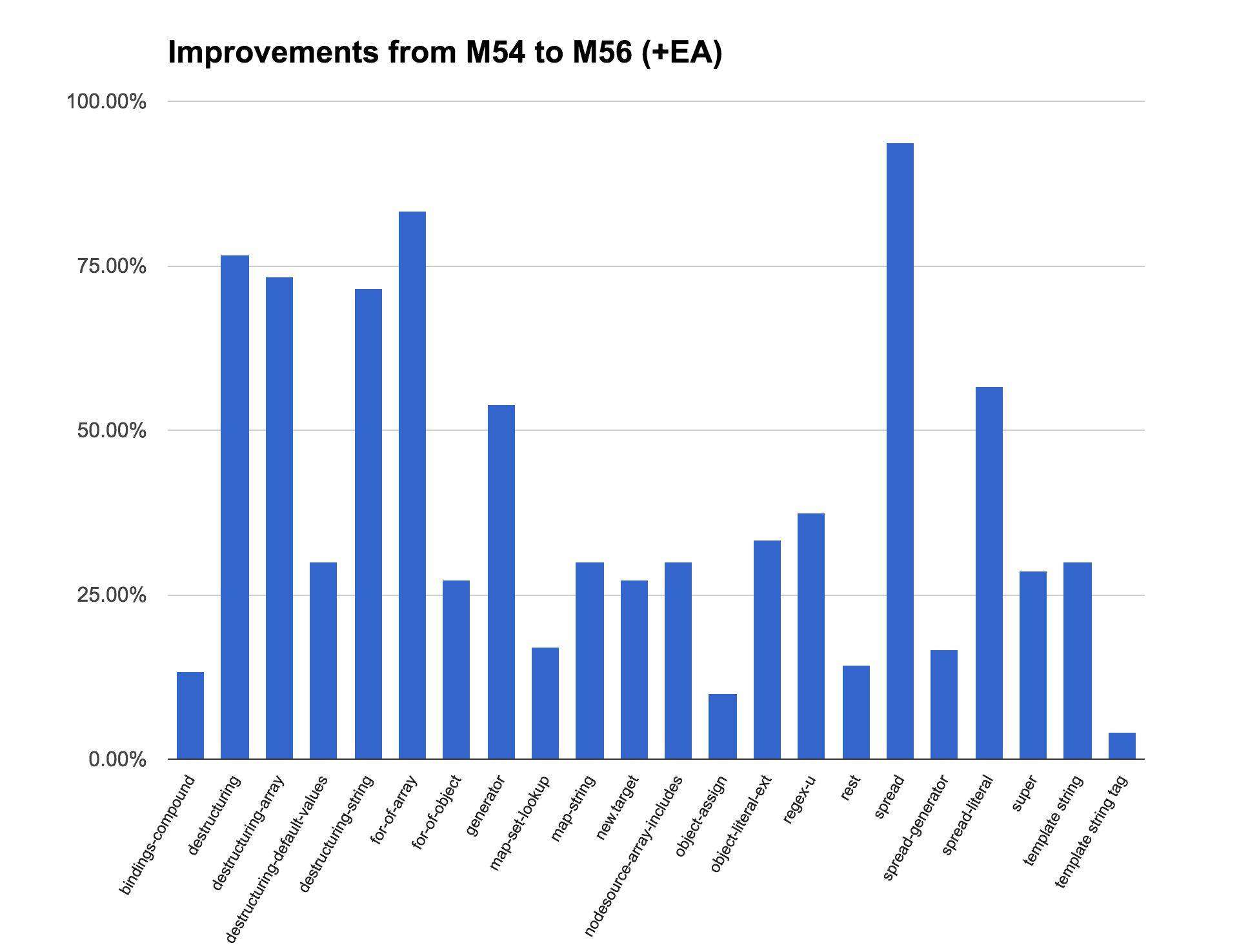
This shows the improvements from V8 5.4 (which ships in current stable Chrome) to V8 5.6 (which will be in Chrome M56), with the additional constraint that I passed the --turbo-escape flag to V8, which unfortunately didn't make it into 5.6 because the TurboFan Escape Analysis was not considered ready for prime time (it's now on in ToT since crrev.com/2512733003). The chart shows the percentage of improvements on the ES5 to ES6 factor. There are still a couple of benchmarks left where we are not yet below 2x, and we are actively working on those, and we hope that we will be able to offer a solid ES2015 experience (performance- and tooling-wise) for the next Node.js LTS release.
A closer look at instanceof #
Besides the line items on the six-speed table, we're also actively working to improve the interaction of other new language features, that might not be so obvious on first sight. One particular, recent example that I'd like to mention here, is the instanceof operator in ES2015 and the newly introduced well-known symbol @@hasInstance. When we worked on implementing ES2015 in V8, we didn't have the resources to fully optimize every feature from the beginning, and we had to make sure that we don't regress existing workloads and benchmarks just because of new ES2015 language features (which was still not possible 100% of the time, but nevertheless we managed to ship almost all of ES2015 by the end of last year without any major performance regressions). But especially the newly added well-known symbols caused some trouble there, as they are not local in the sense of pay for what you use, but are sort of global.

For example, for instanceof, you now need to always check whether the right-hand side has a method @@hasInstance, and use that instead of the old ES5 algorithm - now known as OrdinaryHasInstance - when present, even though in 99.99% of the cases this will be Function.prototype[@@hasInstance], which itself just calls to OrdinaryHasInstance. So for example a function isA like this
function A() { ... }
...
function isA(o) { return o instanceof A; }would be slowed down a lot if you implement ES2015 naively, because in addition to the actual prototype chain walk that you need to perform for instanceof, you know also need to lookup the @@hasInstance property on A's prototype first and call that method. To mitigate that problem we decided to go with a mechanism called a protector cell in the beginning, which allows certain parts of V8 to assume that a certain event didn't happen so far, so we don't need to perform certain checks. In this case the protector cell would guard against the addition of a property named Symbol.hasInstance anywhere in V8. Assuming that no one installed any other @@hasInstance function anywhere, we could just continue to always implement instanceof via OrdinaryHasInstance as long as the protector is intact.
The assumption was that no one would use this monkey-patching ability for instanceof anytime soon, which buys us some time to come up with a better solution that scales well even in the presence of custom Symbol.hasInstance methods. But apparently this assumption was invalid, since Node.js v7 started using Symbol.hasInstance for their Writable class. This slowed down any use of instanceof in any Node.js by up to a factor of 100 depending on the exact usage pattern. So we had to look for mitigations of the problem, and as it turned out, there is at least an easy way to avoid depending on the global protector cell for the optimizing compilers Crankshaft and TurboFan, and so we got that fixed with crrev.com/2504263004 and crrev.com/2511223003.
For TurboFan, I did not only fix the regression, but also made it possible to optimize appropriately in the presence of custom Symbol.hasInstance handlers, which makes it possible to (mis)use instanceof for rather crazy things like this
var Even = {
[Symbol.hasInstance](x) {
return x % 2 == 0;
}
};
function isEven(x) {
return x instanceof Even;
}
isEven(1); // false
isEven(2); // trueand still generate awesome code for it. Assuming we run this example function with the new pipeline (Ignition and TurboFan) using --turbo and --ignition-staging, TurboFan is able to produce the following (close to perfect) code on x64:
...SNIP...
0x30e579704073 19 488b4510 REX.W movq rax,[rbp+0x10]
0x30e579704077 23 48c1e820 REX.W shrq rax, 32
0x30e57970407b 27 83f800 cmpl rax,0x0
0x30e57970407e 30 0f9cc3 setll bl
0x30e579704081 33 0fb6db movzxbl rbx,rbx
0x30e579704084 36 488b5510 REX.W movq rdx,[rbp+0x10]
0x30e579704088 40 f6c201 testb rdx,0x1
0x30e57970408b 43 0f8563000000 jnz 148 (0x30e5797040f4)
0x30e579704091 49 83fb00 cmpl rbx,0x0
0x30e579704094 52 0f8537000000 jnz 113 (0x30e5797040d1)
-- B4 start --
0x30e57970409a 58 83e001 andl rax,0x1
-- B9 start --
0x30e57970409d 61 83f800 cmpl rax,0x0
0x30e5797040a0 64 0f8409000000 jz 79 (0x30e5797040af)
-- B10 start --
0x30e5797040a6 70 498b45c0 REX.W movq rax,[r13-0x40]
0x30e5797040aa 74 e904000000 jmp 83 (0x30e5797040b3)
-- B11 start --
0x30e5797040af 79 498b45b8 REX.W movq rax,[r13-0x48]
-- B12 start (deconstruct frame) --
0x30e5797040b3 83 488be5 REX.W movq rsp,rbp
0x30e5797040b6 86 5d pop rbp
0x30e5797040b7 87 c21000 ret 0x10
...SNIP...
We are not only able to inline the custom Even[Symbol.hasInstance]() method, but TurboFan also consumes the integer feedback that Ignition collected for the modulus operator and turns the x % 2 into a bitwise-and operation. There are still a couple of details that could be better about this code, but as mentioned above we're still working to improve TurboFan.

The engineers behind all of this #
Last but not least, I'd like to highlight that all of this is only possible because we have so many great engineers working on this, and we are obviously standing on the shoulders of giants. Here are the people currently working on features related to ES2015 and beyond for Node.js and Chrome:
- Adam Klein
- Caitlin Potter
- Daniel Ehrenberg
- Franziska Hinkelmann
- Georg Neis
- Jakob Gruber
- Michael Starzinger
- Peter Marshall
- Sathya Gunasekaran
And obviously there are the people who contributed a lot to ES6 itself and the initial V8 implementation:
So if you ever happen to meet one of them, and you like what they're doing, consider inviting them for a beer or two.