Restoring for..in peak performance
When we launched Ignition and TurboFan earlier this year, we did so knowing it wouldn't be overall positive, but that we'll see performance regressions in several cases which we need to address in later releases. Most of these regressions were just a couple percent here and there, with a few significant regressions. Among the most serious regressions was the 4-5x performance hit on for..in peak performance, which was also highlighted in the Get ready: A new V8 is coming, Node.js performance is changing blog post in the summer, and led to some complaints in the community.
Motivation #
That blog post contains a micro-benchmark to measure performance of object iteration, which contains a test using the common pattern consisting of for..in with Object.prototype.hasOwnProperty guards:
var obj = {
x: 1,
y: 1,
z: 1
};
var total = 0;
for (var prop in obj) {
if (obj.hasOwnProperty(prop)) {
total += obj[prop];
}
}Note that in this particular case, the Object#hasOwnProperty guard is not used properly, because the lookup happens on the obj itself, which leads to potential performance issues, i.e. if you pass many different shapes of objects then the obj.hasOwnProperty access will become megamorphic, but might also turn into a correctness issue, i.e. if obj has a null prototype because obj was created via Object.create(null), then the expression obj.hasOwnProperty will raise an error. So make sure to always follow the advice to write Object.prototype.hasOwnProperty.call(obj, prop) instead, which is safe and avoids the potential negative performance impact:
var obj = {
x: 1,
y: 1,
z: 1
};
var total = 0;
for (var prop in obj) {
if (Object.prototype.hasOwnProperty.call(obj, prop)) {
total += obj[prop];
}
}In this case, it doesn't really matter, because obj always has a single shape and always has the Object.prototype as its prototype, so the lookup of obj.hasOwnProperty is both fast and safe.
However looking at the performance of the micro-benchmarks in different V8 versions shows a significant drop in performance with the release of V8 5.9, which is when we launched Ignition and TurboFan.
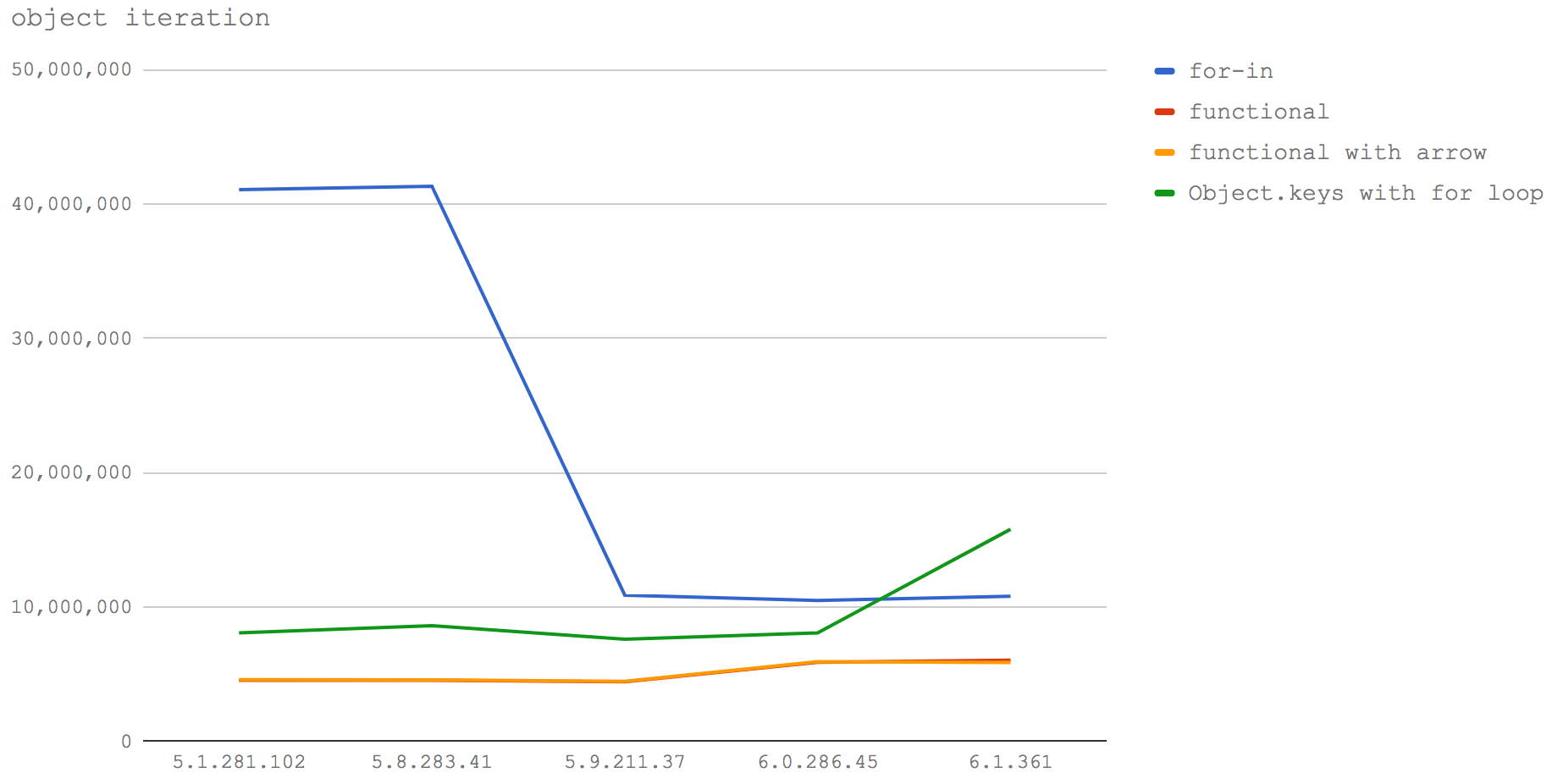
In earlier versions of V8 up to 5.8, using for..in was by far the fastest way to loop over an object's (own) properties and access the values. It was almost 5 times faster than the next closest approach, which is using the Object.keys builtin.
"for those who’ve used for-in for its performance benefits it’s going to be a painful moment when we lose a large chunk of speed with no alternative approach available"
Solution #
This was not an acceptable situation, so we had to take action and address this significant performance issue. But before we dive into that, let's recap quickly what happened in Crankshaft land earlier: The fundamental approach to fast for..in in V8 is mostly independent of the tier and the concrete optimizing compiler, i.e. it works with both Ignition and TurboFan (and also worked similarly with Fullcodegen and Crankshaft before we dropped them). This approach is documented in a separate detailed blog post by Camillo Bruni (who still owes me cookies for reading the full blog post).
Now on top of these fundamental concepts, Crankshaft optimized two additional aspects of fast mode for..in loops (i.e. for..in loops where we know from profiling information that only enumerable fast properties on the receiver were considered and the prototype chain didn't contain any enumerable properties or fancy things like proxies):
- A call to
Object#hasOwnPropertyinside such a loop was constant-folded totrueif the object passed to the call is identical to the object whose properties are being enumerated, and the shape of that object didn't change since the beginning of the loop, and the key passed to the call must be the current enumerated property name. This is correct, because fast modefor..inloops iterate only enumerable properties on the receiver itself. - A property access
object[key]inside such a loop was turned into anHLoadFieldByIndexinstruction, using the known index of the value forkeyinside theobject. This additional enum cache indices table is precomputed as part of the enum cache setup.

While the keys in the Enum Cache contain the (String) names of the properties in enumeration order, the indices contain the location of the property values in the object (in the same order). But the indices aren't always available, since not all property values are stored directly on the object (i.e. accessor properties don't have a value, but rather specify a getter function). So even if an Enum Cache with keys is available, the indices might not be available.
We didn't port this to Ignition and TurboFan initially, because there was a rather serious deoptimization loop hidden in this approach, which affected real world applications pretty badly, i.e. in many React applications one of the hottest functions would just run into this deoptimization loop, and eventually after some ping pong between optimized and unoptimized code wouldn't be optimized at all anymore.
So some refactoring of the enum cache was necessary to make sure that TurboFan is able to tell whether it's safe to assume that enum cache indices are available, and it wouldn't run into the same deoptimization loop that was hurting Crankshaft. And finally we had to port the constant-folding of Object.prototype.hasOwnProperty.call(object, key) and the strength reduction of object[key] inside for (var key in object) {...} loops.
Performance #
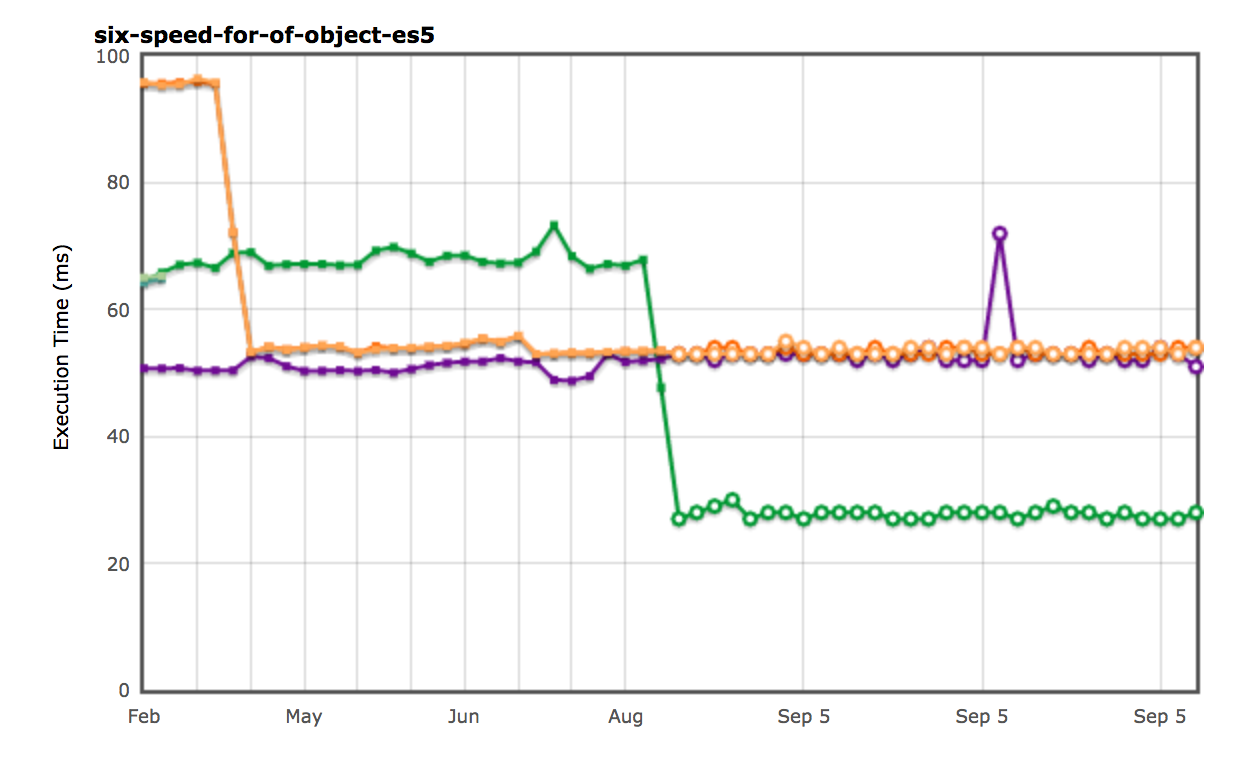
Thanks to the two action items described above, plus general Ignition+TurboFan goodness, the peak performance of for..in was not only restored without adding back the deoptimization loop, but it's also faster than ever before now. For example the execution time of the naive ES5 version of the Six Speed for-of-object test case dropped by almost 60%:
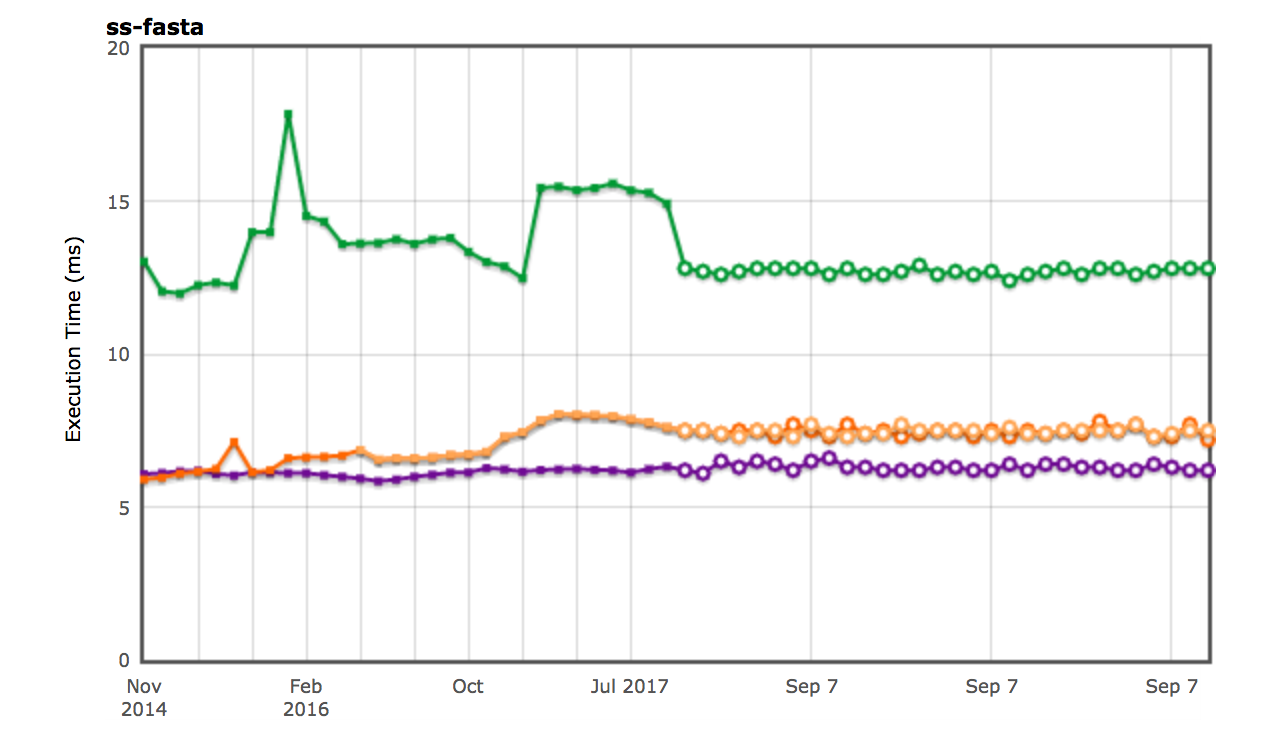
And the performance of the SunSpider string-fasta test, which has been traditionally the only meaningful test case for for..in throughput, was mostly restored as well (the remaining performance difference compared to Crankshaft is due to slightly longer compile times with TurboFan):
I've also assembled a dedicated suite of micro-benchmarks to cover the different aspects of for..in peak performance individually. These are split into six individual test cases, including the test case mentioned in the nearForm blog post.
if (typeof console === "undefined") console = { log: print };
function forIn(o) {
var result = 0;
for (var i in o) {
result += 1;
}
return result;
}
function forInHasOwnProperty(o) {
var result = 0;
for (var i in o) {
if (o.hasOwnProperty(i)) {
result += 1;
}
}
return result;
}
function forInHasOwnPropertySafe(o) {
var result = 0;
for (var i in o) {
if (Object.prototype.hasOwnProperty.call(o, i)) {
result += 1;
}
}
return result;
}
function forInSum(o) {
var result = 0;
for (var i in o) {
result += o[i];
}
return result;
}
function forInSumSafe(o) {
var result = 0;
for (var i in o) {
if (Object.prototype.hasOwnProperty.call(o, i)) {
result += o[i];
}
}
return result;
}
function forInNearForm() {
var o = { x: 1, y: 1, z: 1 };
var result = 0;
for (var i in o) {
if (o.hasOwnProperty(i)) {
result += o[i];
}
}
return result;
}
var TESTS = [
forIn,
forInHasOwnProperty,
forInHasOwnPropertySafe,
forInSum,
forInSumSafe,
forInNearForm
];
var o = { w: 0, x: 1, y: 2, z: 3 };
var n = 1e8;
function test(fn) {
var result;
for (var i = 0; i < n; ++i) result = fn(o);
return result;
}
for (var j = 0; j < TESTS.length; ++j) {
test(TESTS[j]);
}
for (var j = 0; j < TESTS.length; ++j) {
var startTime = Date.now();
test(TESTS[j]);
console.log(TESTS[j].name + ":", Date.now() - startTime, "ms.");
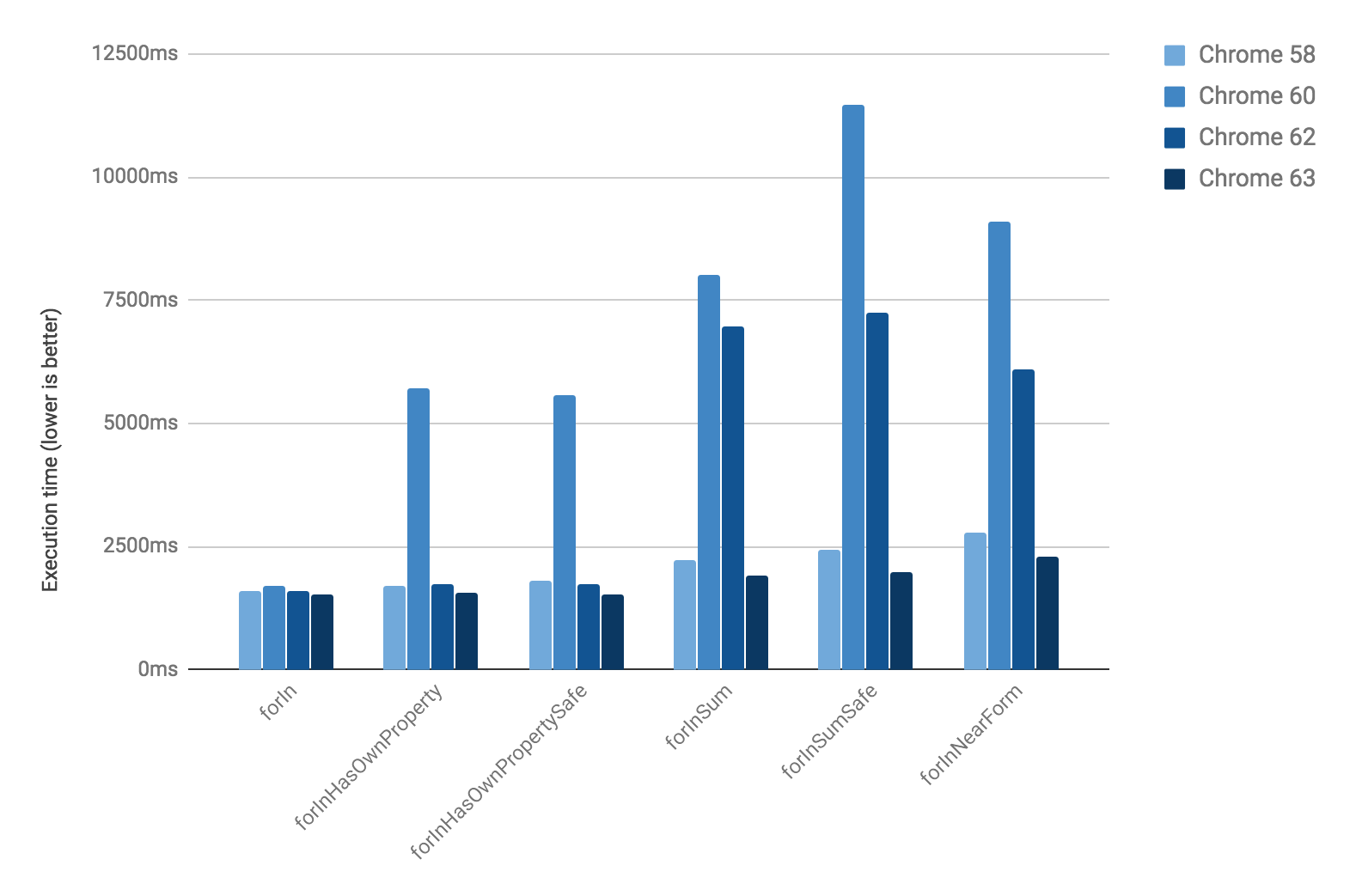
}Running this with different versions of Chrome, we see that we did not only recover the regression fully, but improve beyond the performance of Crankshaft (Crome 58 is the last version with Crankshaft, Chrome 60 has the same V8 version inside as Node 8 at this point):
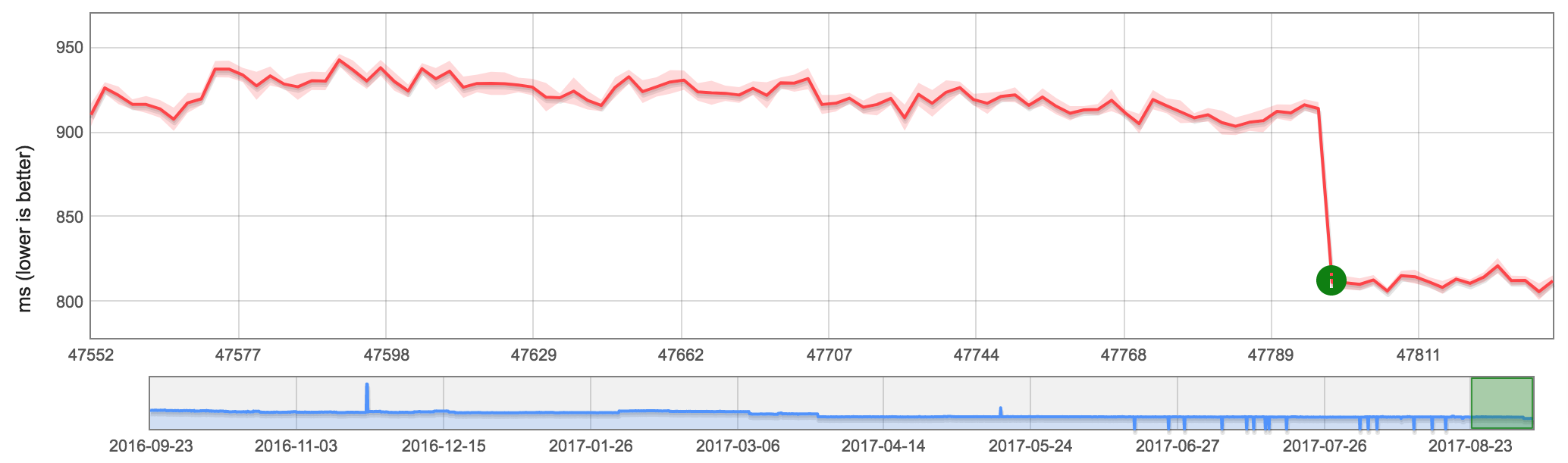
Finally checking the nearForm object-iteration benchmark again with different Node versions to ensure that we really recovered the full regression discovered by that benchmark, and also didn't tank the other versions:
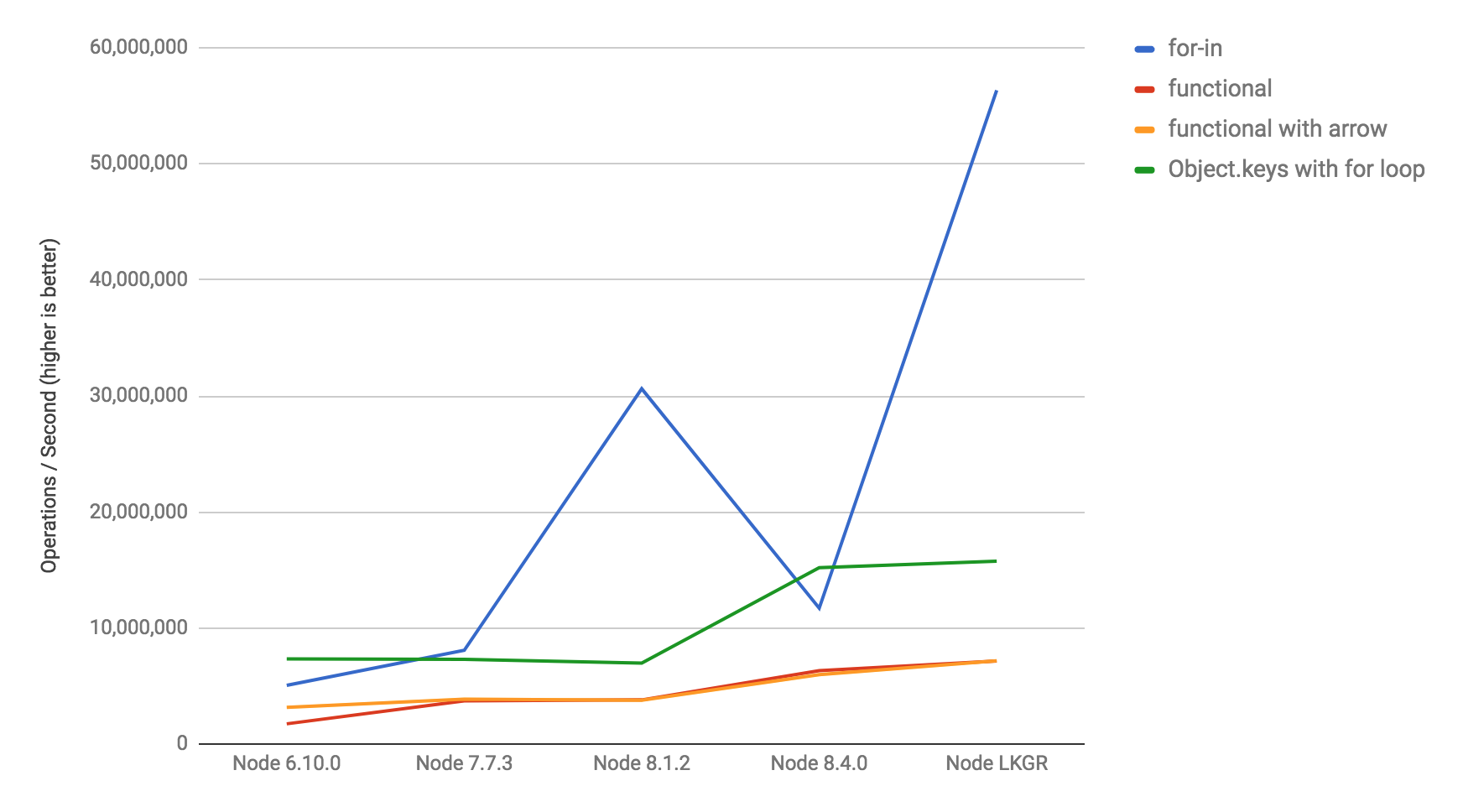
It's worth highlighting that for..in peak performance with the upcoming LTS version will definitely be better than the previous LTS, and at the very least Node 9 will receive a 10x performance boost compared to Node 6 (current LTS).
Besides just micro-benchmarks, it's obviously also interesting to see direct real-world impact of such changes. Not a lot of websites are dominated by for..in peak performance in a way that it makes a real difference, but there's one interesting example that seems to stand out: The time spent in V8 during page load of meta.discourse.org seems to drop by like 13% with these changes: