Connecting the dots
The last months have been a hectic time for me. I was hosting my first intern Juliana Franco at Google working on the Deoptimizer during her internship on lazyiness. Then I was diagnosed with articular gout and almost couldn't walk for a week. And we finally moved into our new house with a lot of help from my awesome colleagues on the V8 team. On the Node.js front, I became the tech lead of Node performance in the V8 team, joined the Node.js benchmarking working group, and I am now officially a Node.js collaborator. But I also had some time to close gaps in V8 performance now that Ignition and TurboFan finally launched everywhere.
So today I'll give an overview of what I've done in V8 land in the last month, which is also a sneak preview of what's going to change performance-wise in V8 6.3 (which will ship as part of Chrome 63 and probably Node 9 at some point). Fortunately most of the changes were straight-forward at this point, because most of the infrastructure for the optimizations is in place already and we only need to connect the dots now.
I'm going to use V8 version 5.8 (which is the last version before we switched to Ignition and TurboFan in Chrome), 6.1 (which is the current stable version in Chrome and also in Node 8) and 6.3 (which is the current development version) for the performance comparisons.
An internship on laziness #
As mentioned above this was the first time I hosted an intern at Google. It sure comes with a lot of work and some additional responsibilities, but it was super exciting. Juliana was an awesome intern. I have to admit that the area that she was working on (lazy deoptimization without code patching and lazy unlinking of deoptimized functions) is not my main area of expertise, so I had to rely a lot on my colleagues Jaroslav Sevcik and Michael Starzinger to help her out. But the end result is just amazing, especially getting rid of the weakly linked list of all closures in V8 is a major accomplishment.
So I'd like to use this opportunity here to say: Thank you, Juliana, for spending the summer with us, it was awesome to have you as an intern!
Object constructor calls in webpack bundles #
I already wrote a detailed article about this topic. To summarize, webpack v3 generates code the following bundled code
var m = __webpack_require__(1);
Object(m.foo)(1, 2); // <- called without this (undefined/global object)for
import foo from "module";
foo(1, 2); // <- called without this (undefined/global object)essentially wrapping the target in the Object constructor to make sure the callee get's passed either undefined if it's in strict mode or the global object if it's a sloppy mode function. By teaching TurboFan about the Object constructor we were able to close the performance gap and make these calls as fast as direct calls or indirect calls via the Function.prototype.call builtin.

What was awesome about this change is that it went viral and soon all major JavaScript engines, including SpiderMonkey, JavaScriptCore and ChakraCore, will support this optimization.
Restoring for..in peak performance #
This was also already described in a detailed blog post. The TL;DR is that when we launched Ignition and TurboFan, we did so with a couple of regressions that we'd need to address once the dust settles. One of the major performance hits was a 4-5x regression in for..in peak performance as noticed in Get ready: A new V8 is coming, Node.js performance is changing.
var obj = {
x: 1,
y: 1,
z: 1
};
var total = 0;
for (var prop in obj) {
if (obj.hasOwnProperty(prop)) {
total += obj[prop];
}
}We managed to not only recover the regression on this micro-benchmark, but even performance compared to previous Node versions. So expect a huge performance boost in Node 9 (might also end up in Node 8 if it turns out to be fine to upgrade V8 during LTS cycles).
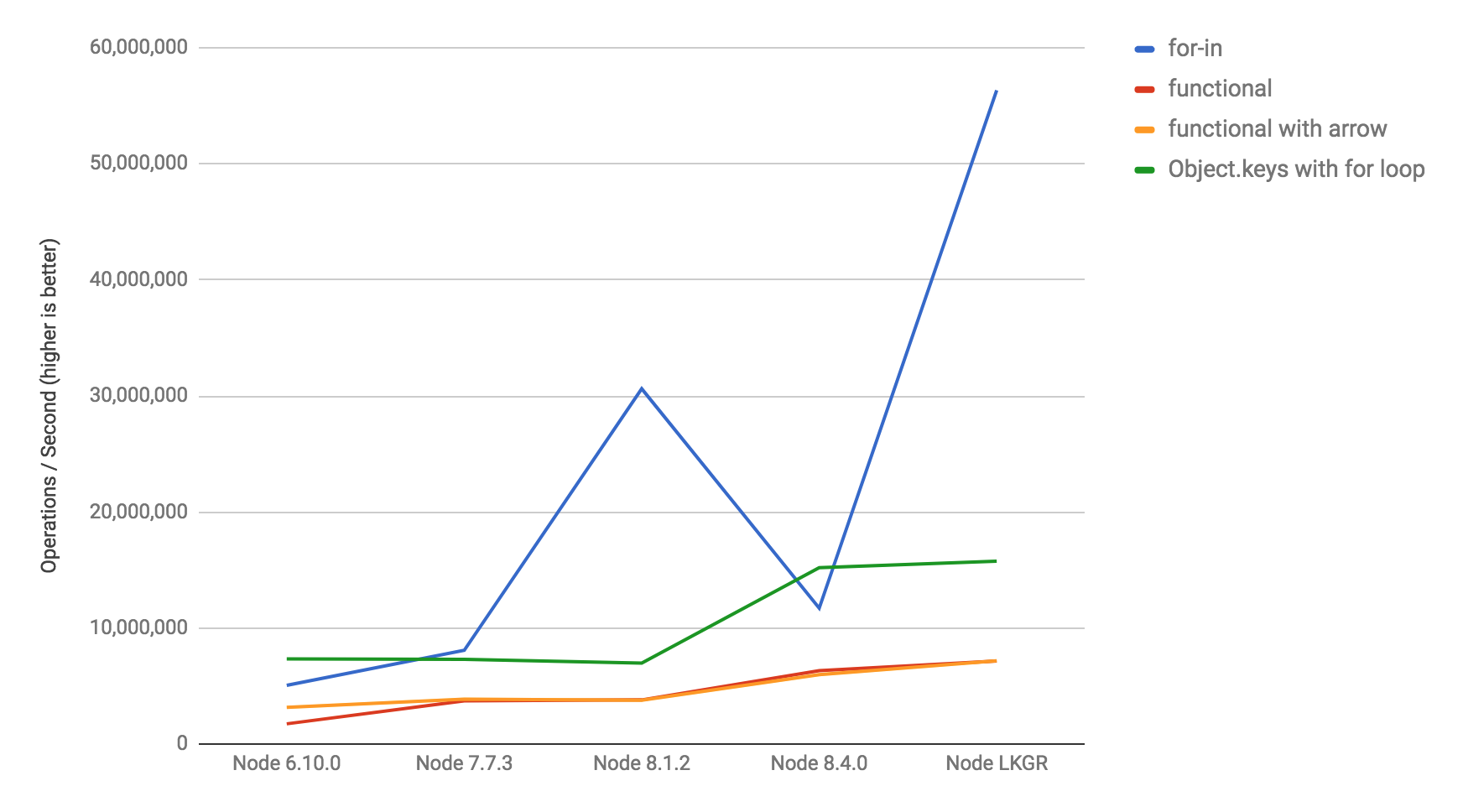
Also worth noting, that despite having regressed from Node 7 to Node 8, the for..in peak performance in the upcoming LTS (Node 8) still improves compared to the previous LTS (Node 6).
Optimize Object constructor subclassing #
Subclassing Object explicitly was about 3-4x times slower (upon instance creation) than just skipping the extends clause completely. While it didn't seem to be useful to write
class A extends Object { ... }instead of just
class A { ... }where the only observable difference will be the prototype chain of the constructor, there's the case of class factories. When you use class factories to stamp out base classes, i.e. as mentioned here and here,
const Factory = BaseClass =>
class A extends BaseClass { ... };
const MyObject = Factory(Object);where code will implicitly extend the Object constructor. Unfortunately V8 didn't do a good job at optimizing this use case, and in particular TurboFan didn't know about it, so we had to introduce some magic to recognize the case where the Object constructor is being used as the base class, so that TurboFan can still fully inline the object instantiation.

Compared to Chrome 58, which is latest version shipping with the old Crankshaft based optimization pipeline, the performance of subclassing Object improved by 5.4x.
Fast-path for TypedArrays in Function.prototype.apply #
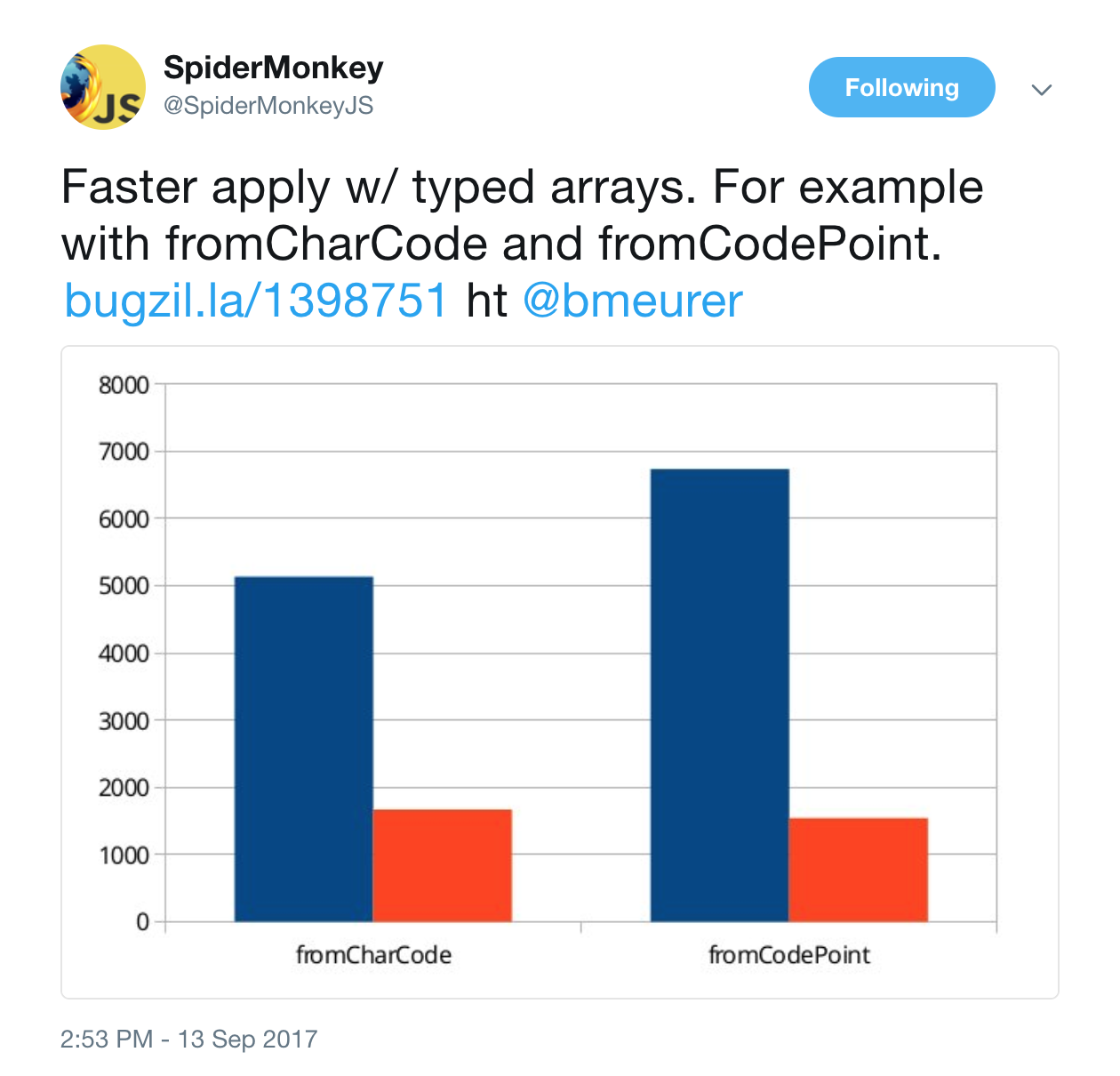
I'm also actively trying to address long-standing issues. One of these was a report from 2012 titled "String.fromcharCode.apply(undefined, uint8Array) is super-slow", which discovered that using Function.prototype.apply with TypedArrays is embarrassingly slow in V8. This is specifically bad, since there's a nice use case in combination with String.fromCharCode to construct Strings from character code sequences encoded in Uint8Arrays or Uint16Arrays.
// convert a typed array to a js string
function ar2str(uint16arr) {
// break the computation into smaller arrays to avoid browser limits on array
// size for .apply() call
var res = [],
i = 0,
len = uint16arr.length,
MAX_ELEMENTS_PER_CALL = 100000;
while (i < len) {
res.push(
String.fromCharCode.apply(
null,
uint16arr.subarray(i, (i += MAX_ELEMENTS_PER_CALL))
)
);
}
return res.join("");
}It turned out to be fairly straight-forward to just add a fast-path for TypedArrays to the %CreateListFromArrayLike C++ runtime function, which is used by Function.prototype.apply under the hood.

So it's a 2.2x to 3.4x improvement compared to Chrome 58, and there's probably still some room for improvement in the future. The same optimization was also later ported to SpiderMonkey, where they observed similar speed-ups.
Optimize Array.prototype.push with multiple parameters #
Earlier last month, SpiderMonkey's André Bargull discovered that Firefox often missed opportunities to inline calls to Array.prototype.push into optimized code, especially visible on the Speedometer Ember test and the six-speed-spread-literal-es5 benchmark:
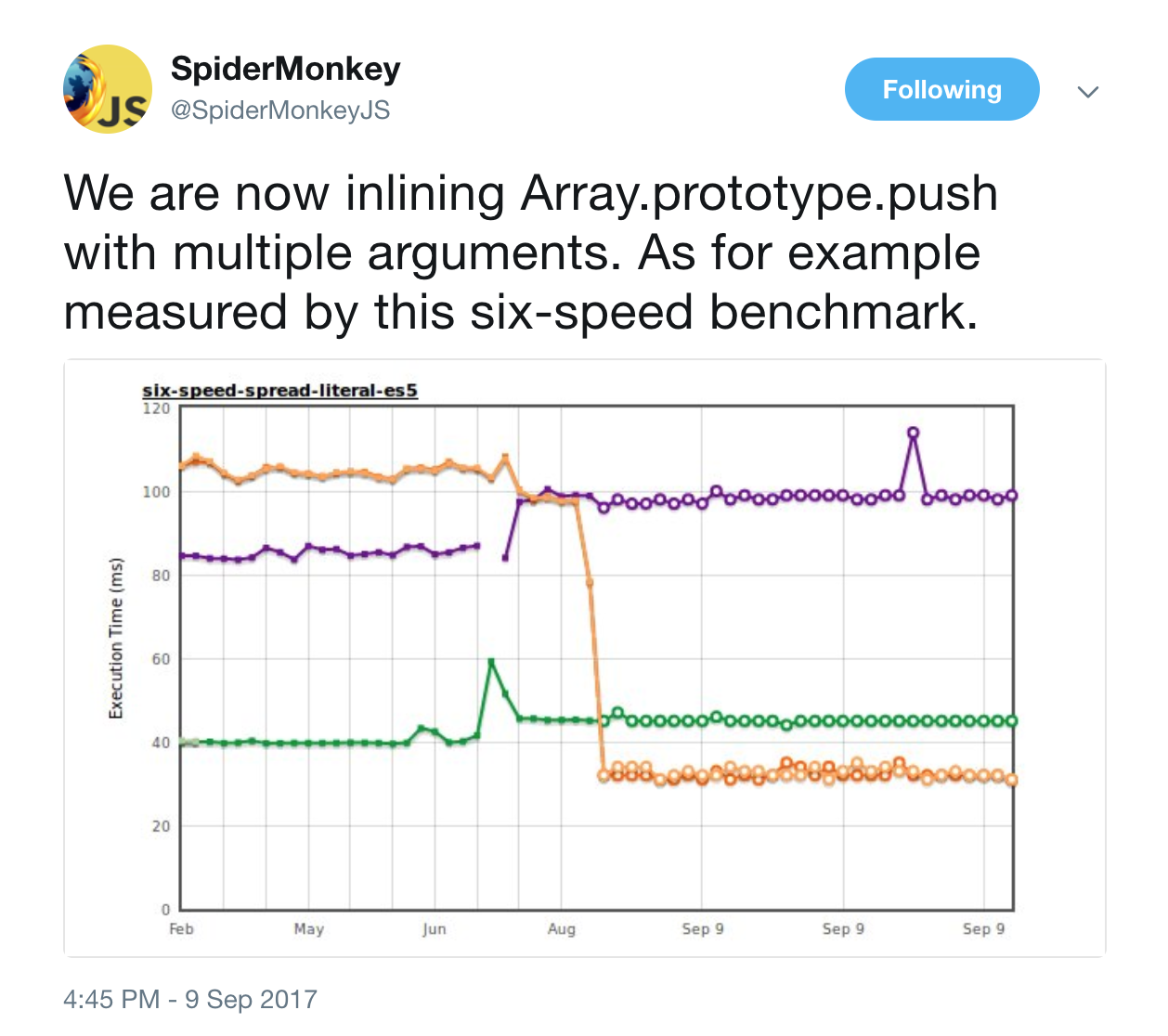
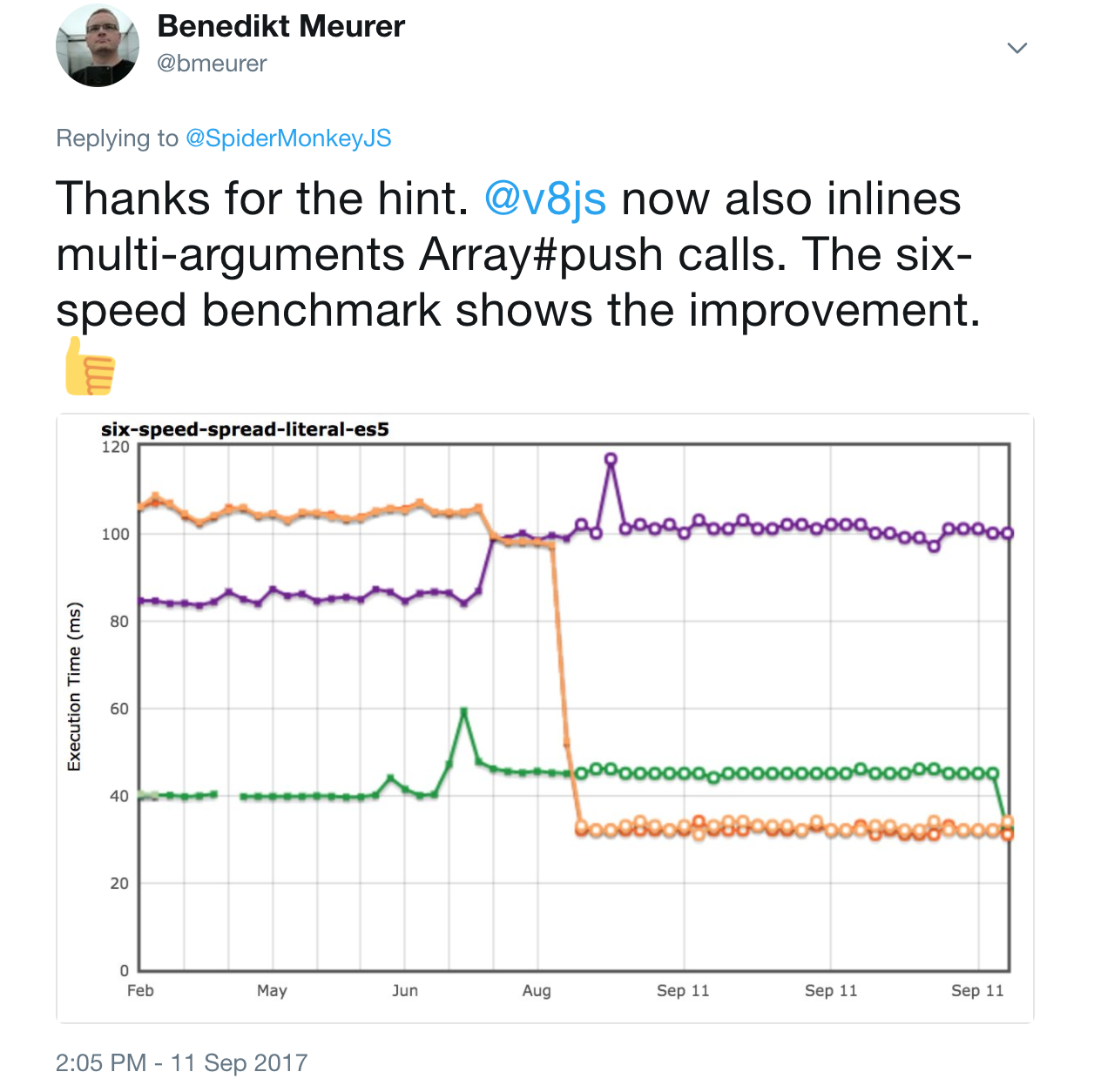
A similar observation had already been made by the JavaScriptCore folks. And it turned out that we were also missing this optimization in V8. So I took the idea from SpiderMonkey and ported it to TurboFan.

This essentially removes the weird performance cliff when going from single argument to multiple arguments in a single call to Array.prototype.push. And we also closed the gap on the six-speed-spread-literal-es5 benchmark.
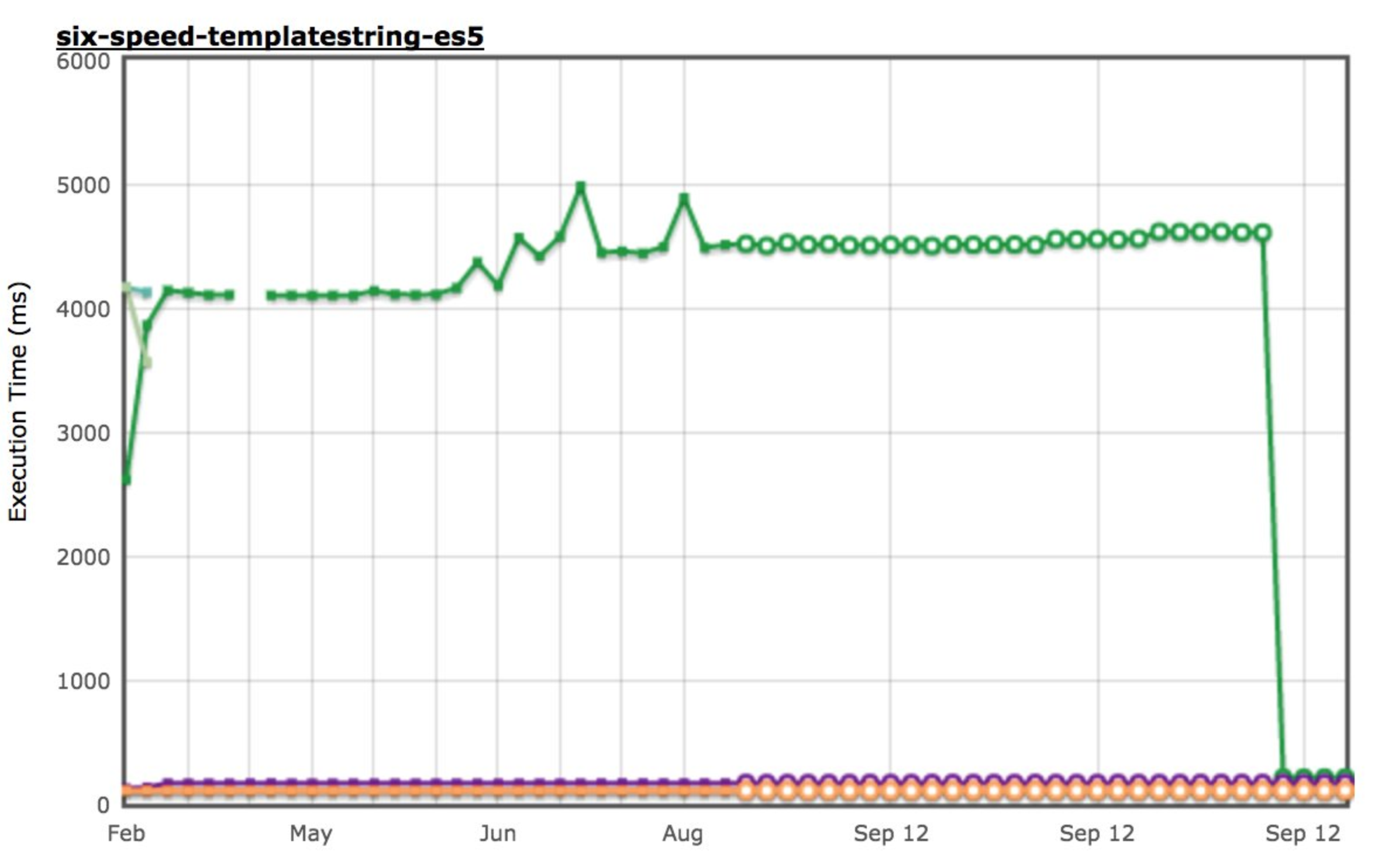
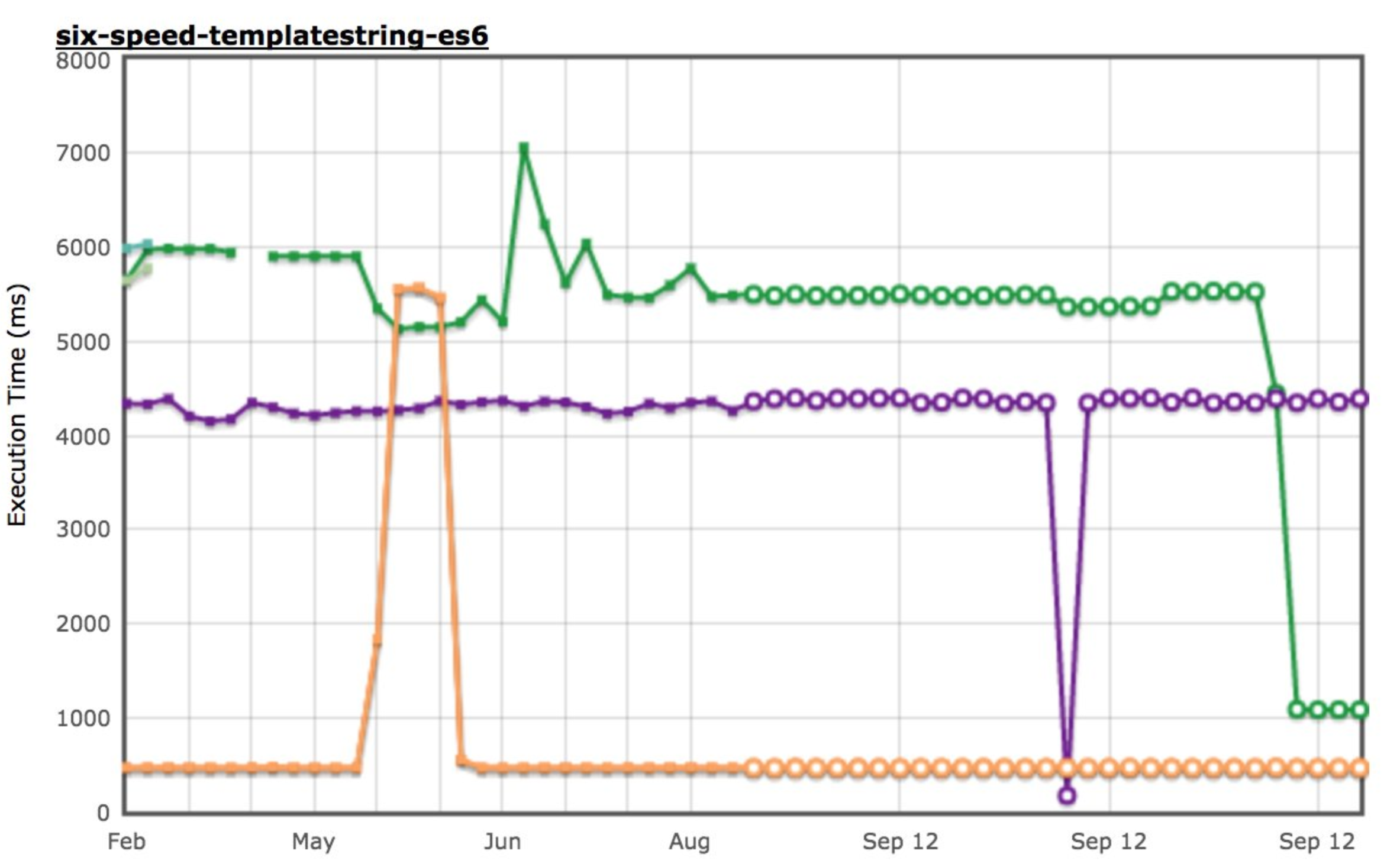
Improved constant-folding #
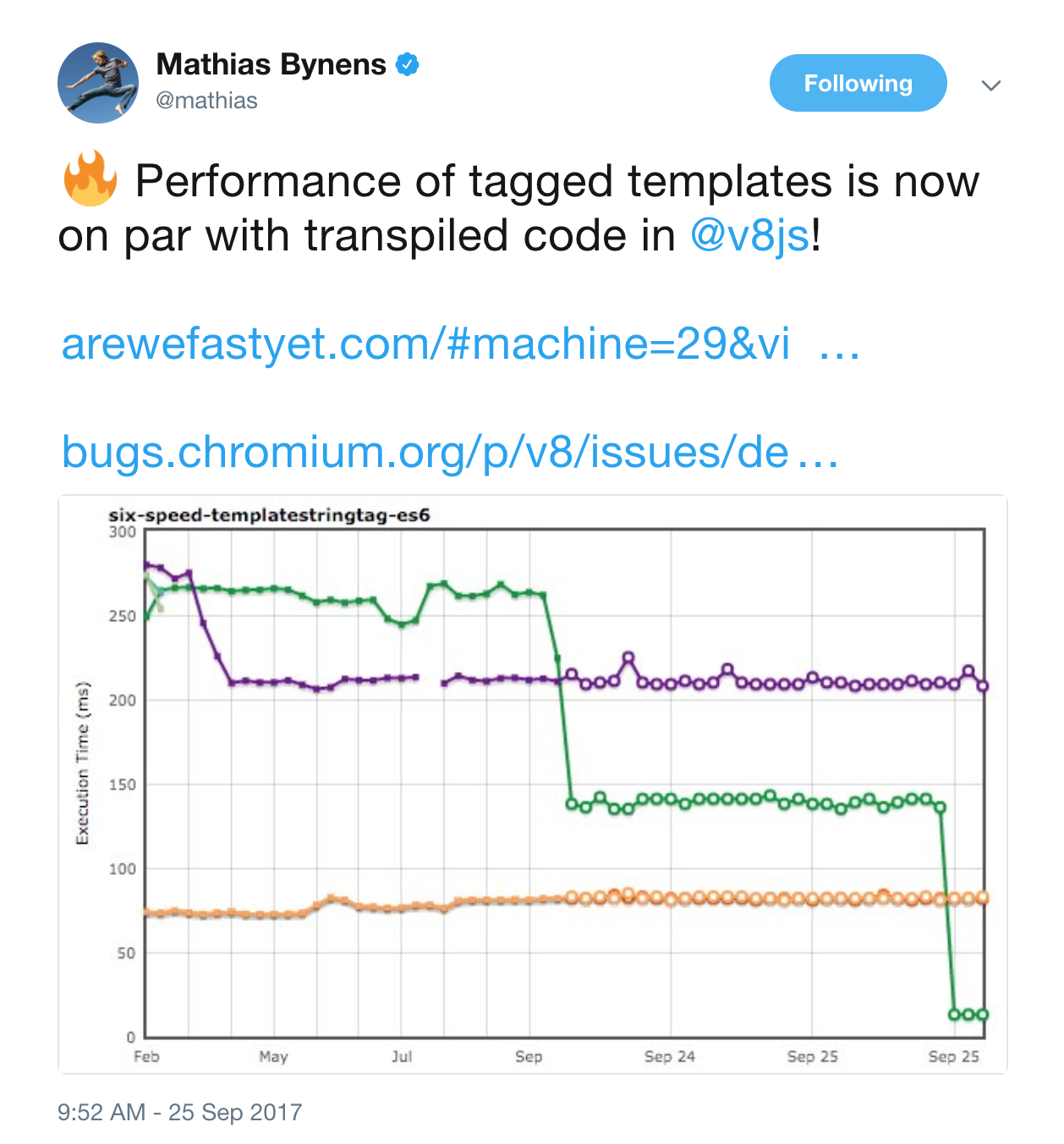
We also realized that TurboFan was missing several opportunities for constant-folding, specifically the six-speed-templatestring-es5 and six-speed-templatestring-es6 made it clear that we weren't doing a good job there (yes, those are micro-benchmarks and the iteration count chosen by arewefastyet is insane, so the impact on real-world will not be 20x unless your application doesn't do anything else). So we connected a couple more dots and observed some massive speed-ups on these benchmarks.
Optimize tagged templates #
Tagged templates are one of the coolest features introduced with ES2015 - if you ask me 😛. I specifically love the Computing tag functions for ES6 template literals idea, i.e.:
/**
* Tag function that returns a string that conforms
* to the normal (“cooked”) interpretation of
* template literals.
* `String.raw` is similar, but follows the “raw”
* interpretation.
*/
function cook(strs, ...substs) {
return substs.reduce((prev, cur, i) => prev + cur + strs[i + 1], strs[0]);
}
function repeat(times) {
return function(...args) {
return cook(...args).repeat(times);
};
}
repeat(3)`abc${3 + 1}`; // produces "abc4abc4abc4"Here the language specification even requires implementations to cache the so-called TemplateObject to actively encourage constant-folding and avoid recomputation when going to optimized code. Unfortunately we didn't really take advantage of that so far. So I started teaching both Ignition and TurboFan about template objects, which brought the ES6 implementation on par with the Babel transpiled code. Once that was done, we looked into constant-folding sealed properties consistently, i.e. own properties of objects that were either frozen via Object.freeze or sealed via Object.seal.

Together these changes yielded a massive performance improvement of up to 23x and helped us to boost the six-speed-templatestringtag-es6 benchmark even further (keep in mind that this is a micro-benchmark).
Properly optimize literals in inlined functions #
Then I stumbled upon a bug in TurboFan where it would not always optimize array, object or regular expression literals properly when they occur in inlined functions. So for example, let's say you have code like this
function foo() {
function bar() {
return { x: 1 };
}
return bar().x;
}then bar will likely be inlined into foo during optimization, but the literal {x:1} will not be turned into an inline allocation, and instead call out to a generic code stub - the FastCloneShallowObject builtin - which is a lot slower than an inlined allocation, that can also be escape analyzed away. Interestingly, changing the code slightly to
function bar() {
return { x: 1 };
}
function foo() {
return bar().x;
}so that TurboFan inlines based on the concrete closure, JSFunction in V8 speak, we don't emit any code for the literal, but just return 1 as expected. Turns out that this was just a left over from a previous refactoring (when we moved the literal boilerplates to the FeedbackVector). So finishing the refactoring and always specializing literals like any other feedback fixes this fancy performance cliff, yielding a roughly 3x to 4x performance improvement compared to Chrome 61, and almost an 8x improvement compared to Chrome 58 (which didn't get the inlining right for this case), on the micro-benchmarks from the tracking bug.

Optimize ArrayBuffer view checks #
Last week I was dragged into a conversion regarding nodejs/node#15663 and what could be done on the V8 side to help improve performance of these predicates. It turned out that all the relevant builtins for either checking whether something is any ArrayBuffer view (i.e. either a TypedArray or a DataView), a concrete TypedArray like Uint8Array, or just any TypedArray, weren't really optimized in V8 (neither the baseline implementation nor the treatment inside TurboFan). Specifically to check for whether something is a TypedArray, the best (and maybe only) way to do this now is to use the TypedArray.prototype[@@toStringTag] getter, i.e. the pattern looks like this (as found in lib/internal/util/types.js):
const ReflectApply = Reflect.apply;
function uncurryThis(func) {
return (thisArg, ...args) => ReflectApply(func, thisArg, args);
}
const TypedArrayPrototype = Object.getPrototypeOf(Uint8Array.prototype);
const TypedArrayProto_toStringTag = uncurryThis(
Object.getOwnPropertyDescriptor(TypedArrayPrototype, Symbol.toStringTag).get
);
function isTypedArray(value) {
return TypedArrayProto_toStringTag(value) !== undefined;
}
function isUint8Array(value) {
return TypedArrayProto_toStringTag(value) === "Uint8Array";
}
const isArrayBufferView = ArrayBuffer.isView;Now you can use isTypedArray(x) to check whether x is any TypedArray, and isUint8Array(x) to check whether x is an Uint8Array. TurboFan was already doing a good job at Reflect.apply and also dealing well with the rest parameters in uncurryThis. So all that was left was to optimize ArrayBuffer.isView for the general check and TypedArray.prototype[@@toStringTag] getter for the TypedArray checks.
The former was straight-forward, just adding a new ObjectIsArrayBufferView predicate to TurboFan and lowering calls to ArrayBuffer.isView to this newly introduced predicate. The latter was a bit more involved, and required both changes to the baseline implementation and the TurboFan treatment. The fundamental idea was to use the fact that each kind of TypedArray has a specific elements kind, i.e. UINT8_ELEMENTS, FLOAT64_ELEMENTS, and so on. So the implementation now simply switches on the elements kind on the hidden class of the receiver and returns the proper String or undefined if it's not a TypedArray.

We observe up to 14.5x performance improvements compared to Chrome 58.
Miserable performance when storing booleans in typed arrays #
This week's monday morning exercise. Every now and then some people ping some long-standing bugs hoping that someone would pick them up and fix them. In this case it was the infamous Chromium bug 287773, which was originally reported in late 2013, so more than 4 years ago. The reported problem is that storing booleans to typed arrays leads to really bad performance in V8. I have to admit that I've been ignoring this bug for a while, since it wasn't really trivial to fix in Crankshaft when I saw the bug for the first time, and then forgot about it. But thanks to TurboFan fixing this bug was a no brainer: We just need to update the KEYED_STORE_IC to truncate true, false, undefined and null to numbers instead of sending the IC to MEGAMORPHIC state, and also tell TurboFan to properly convert the right-hand side of the assignment to a number first (if it's not already a number).

With this in place the performance of storing true or false to a TypedArray is now identical to storing integers, compared to Chrome 61 that's a solid 70x improvement.
Polymorphic symbol lookup not well supported #
Later that same day Slava popped up with an issue that the Dart folks ran into.
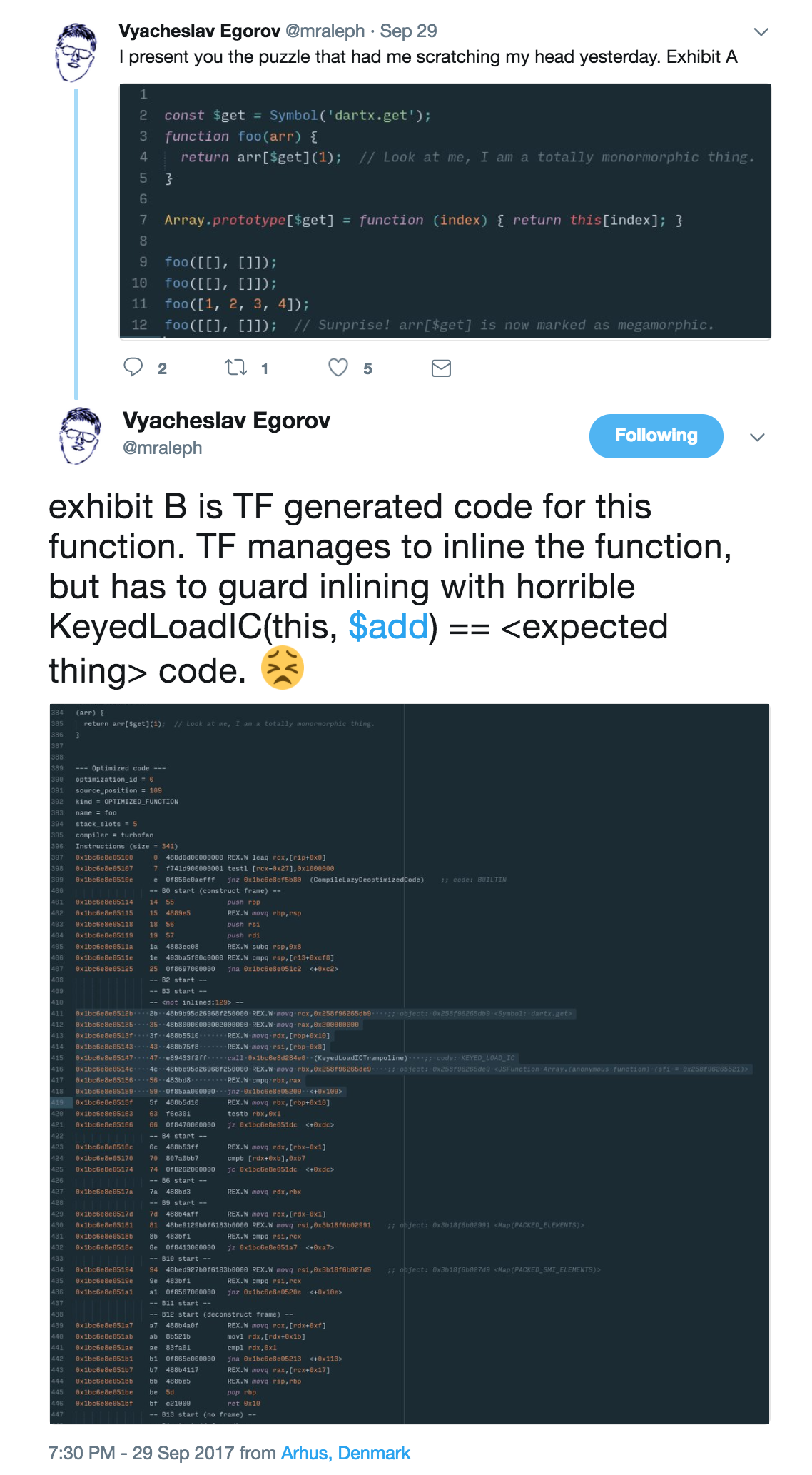
This looked suspiciously similar to V8 issue 6367 that we had noticed before, but hadn't had the time to dig into. The underlying issue is that for code like
const sym = Symbol();
function foo(o) {
return o[sym];
}we don't deal well with the case where o has different hidden classes on the access to o[sym]. The responsible KEYED_LOAD_IC would immediately go to MEGAMORPHIC state (read: become generic) when it sees more than one hidden class for o. Doing the same with string names using the dot syntax, i.e.
function foo(o) {
return o.str;
}is just fine and can handle up to 4 different hidden classes for o until it decides to go MEGAMORPHIC. Interestingly I discovered that this was not a fundamental problem, in fact most of the relevant components in V8 could already deal with multiple hidden classes even for the KEYED_LOAD_IC, so it was merely a matter of connecting the dots again (plus some yak shaving to repair a bug that I flushed out with the initial CL) to fix the odd performance cliff with polymorphic Symbol lookups.

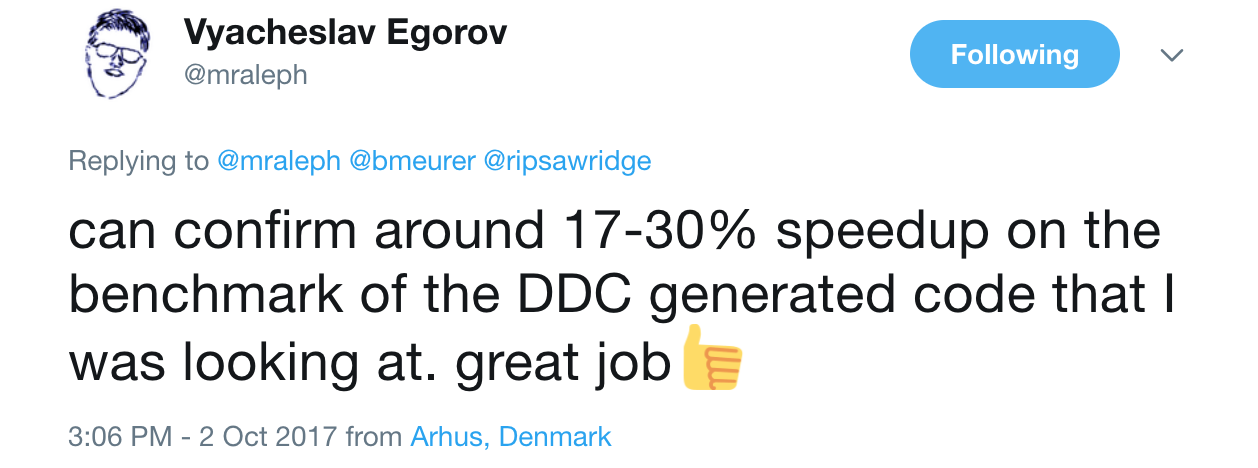
But that still didn't fully cover the case for V8 issue 6367, which was about the clone pattern (as discovered in the ARES6 ML benchmark):
class A {
static get [Symbol.species]() {
return this;
}
clone() {
return new this.constructor[Symbol.species]();
}
}
class B extends A {
static get [Symbol.species]() {
return this;
}
}
function foo(o) {
return o.clone();
}
foo(new A());
foo(new B());It turned out that while the polymorphic symbol lookup in this.constructor[Symbol.species] was addressed by the above mentioned fix, TurboFan would still refuse to inline the polymorphic constructor call in new this.constructor[Symbol.species](), constructing either an instance of A or an instance of B depending on this. Again, it turned out that this was not something fundamental, but just two trivial issues where some parts of TurboFan were blocking the optimization. Removing that we got an overall 7.2x combined performance boost for the clone pattern above.
Improve performance of Object.is #
And one last issue that also originated in Node land. It turns out that Object.is(x,-0) is a very elegant way to check whether an arbitrary value is minus zero, which is useful in several cases, for example when you want to print -0 as "-0" instead of "0" (which is what the ToString operation yields otherwise).
Unfortunately Object.is was previously implemented as C++ builtin, despite having all the logic for a fast CodeStubAssembler based version in place already. Also TurboFan didn't really know anything about Object.is, not even for the fairly simple cases where one side is statically known to be -0 or NaN (the interesting cases), or where both inputs refer to the same SSA value, which can be constant-folded to true easily since Object.is identifies NaNs (in contrast to strict equality).
As mentioned we had all the building blocks in place to handle Object.is in a fast way, so it was merely an exercise in porting the existing implementation and hooking it up to TurboFan.

So performance of Object.is improved by up to 14x since Chrome 58, and starting with Chrome 63 and/or Node 9, it should be fine performance-wise to use Object.is, especially for the edge case checks, i.e. checking for -0 or checking for NaN.
Conclusion #
Congratulations, you made it through the whole blog post! 😉 No you won't get cookies, sorry...
But joking aside, these are exciting times. We had been busy with working on the long-term architectural changes around Ignition and TurboFan - by the way I'll be giving a talk at JS Kongress this year titled "A Tale of TurboFan: Four years that changed V8 forever" - and now we're finally back in a state where we can move quickly and improve performance by just closing the gaps. I feel like JavaScript has a bright future.
